blog
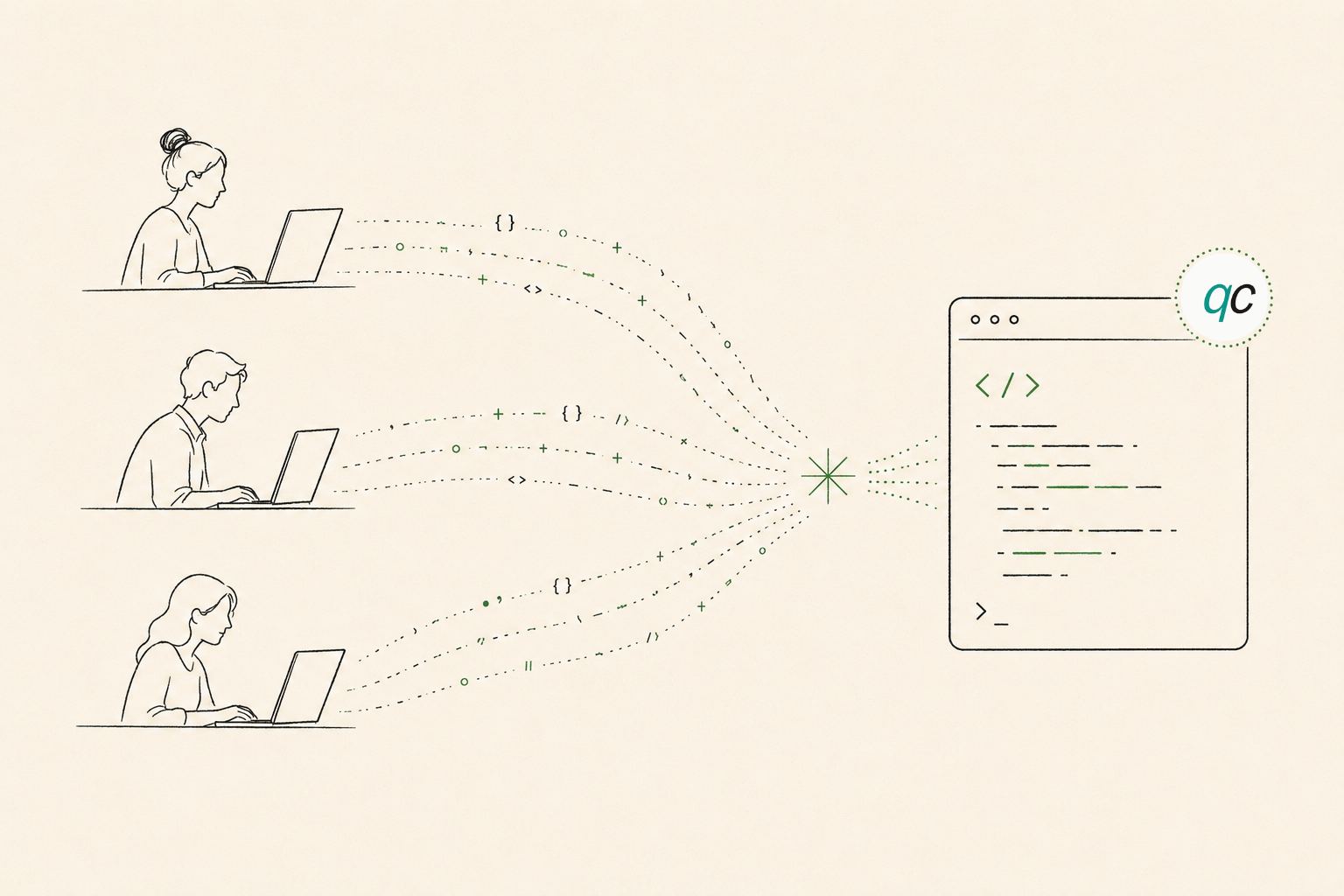
Your Team Has a Secret Language
Why AI coding agents start as strangers and what team traces reveal about the knowledge that lives between developers

The New Mac Ritual: A Dev Setup Playbook
Personal log for setting up a fresh MacBook — so I don't have to think about it next time
What the MCP? (Part 3): When Code LLMs Need Help
Everyone's adding MCP servers. Few are thinking about how they'll actually be called correctly.

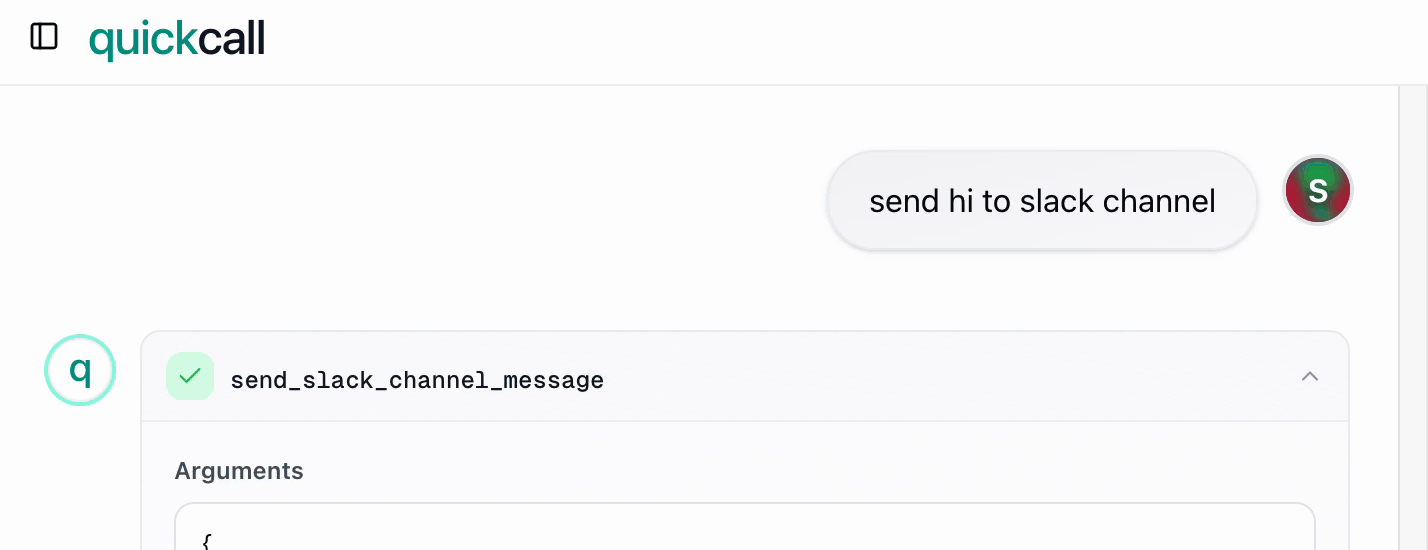
What the MCP? (Part 2): I Built Quick Call
I set out to write Part 2 about MCP. Instead, I fell into a rabbit hole...

What the MCP? (Part 1)
Understanding Model Context Protocol and why it's different from function calling
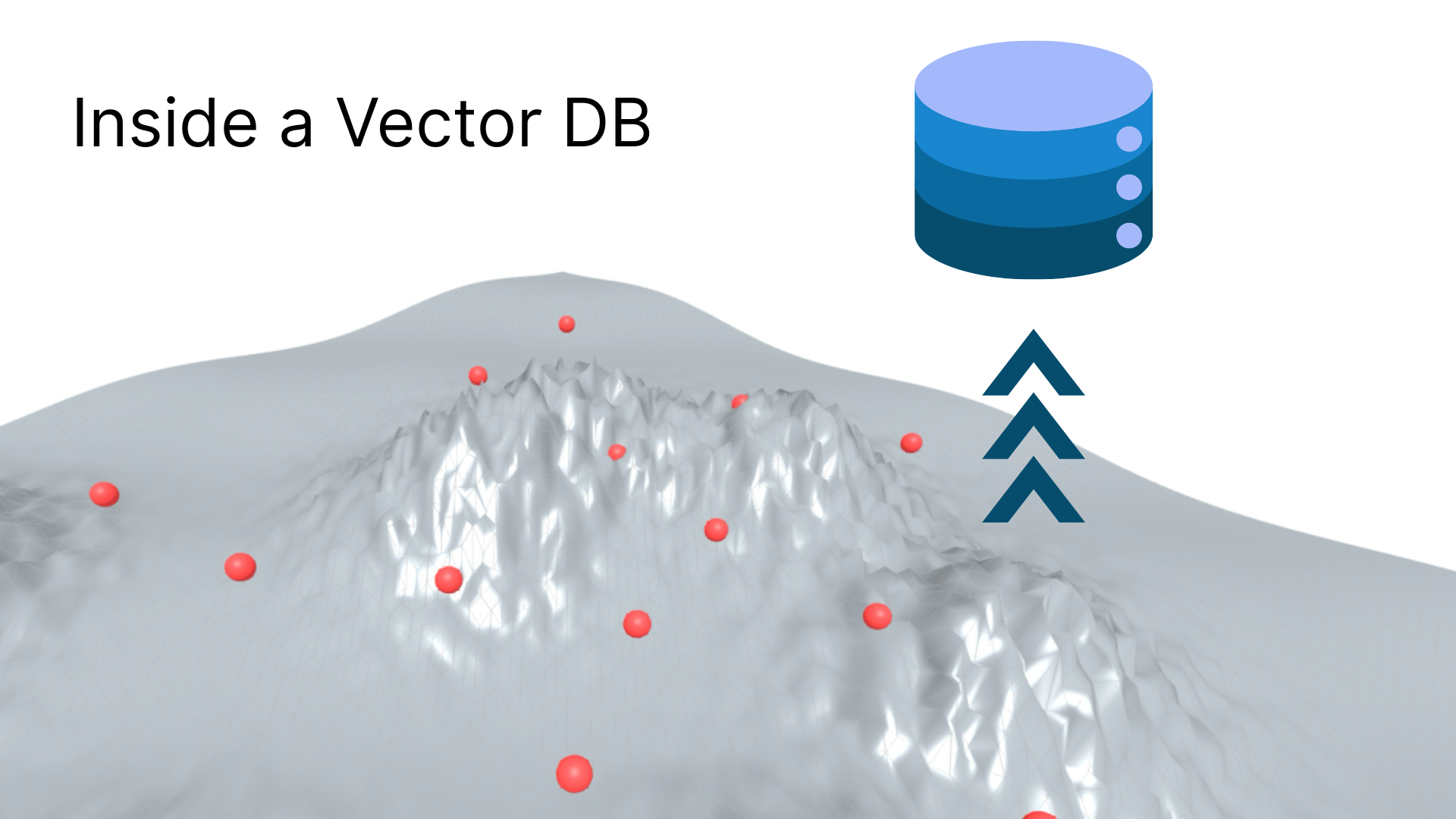
Inside VectorDB
How VectorDBs work under the hood
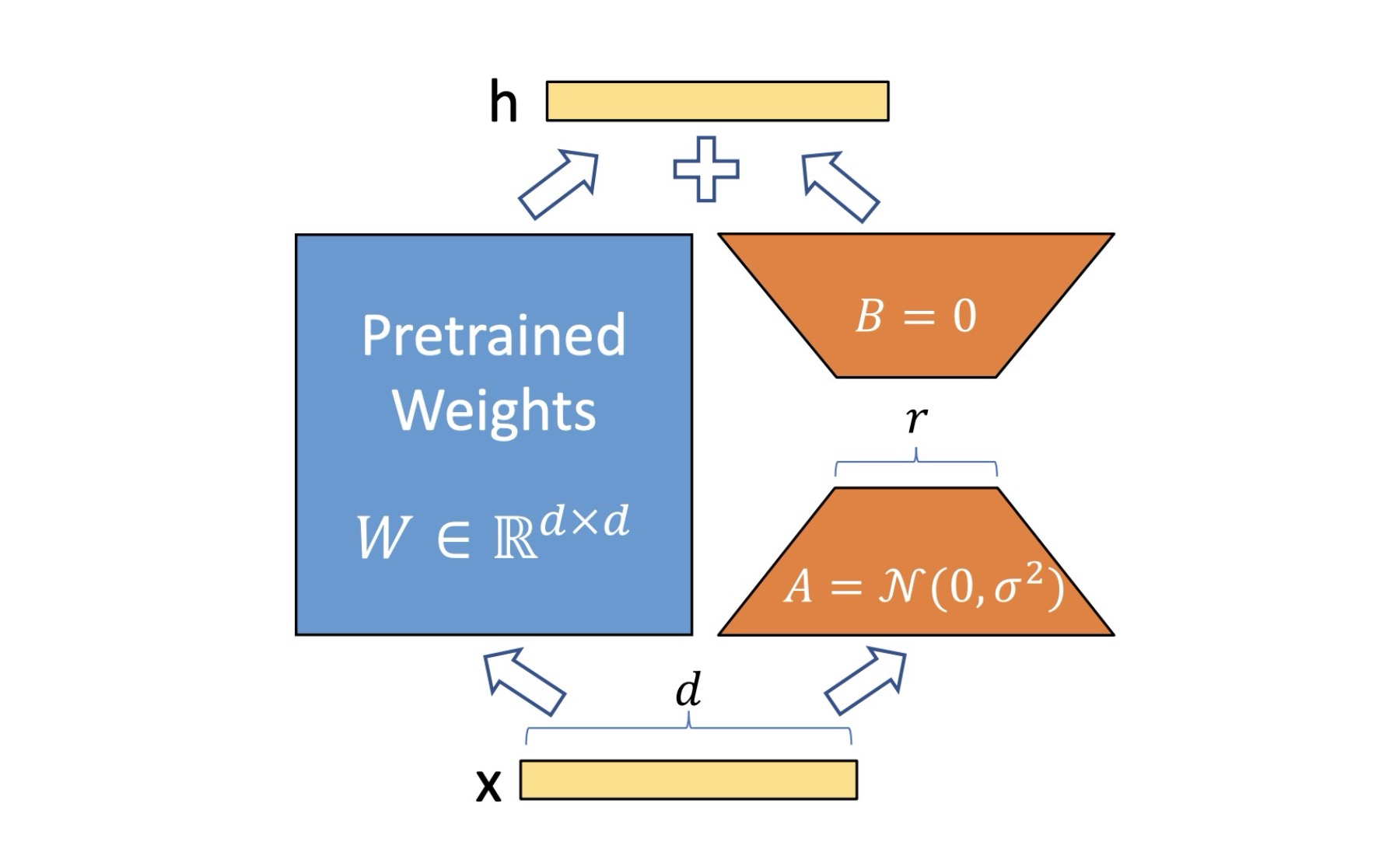
Deep Dive into LoRA: A Practical Exploration
Secret sauce to train large language models

KV Caching in LLMs: A Visual Demonstration
A visual demonstration of KV caching in language models

Inputs to Byte Latent Transformer
Part 2 of All you need to know to get started with Byte Latent Transformer

Ten Trillion Tokens: Making AI Work for Every Indian Language
Building the largest multilingual LLM dataset for Indian languages at People+AI

Precursors to Byte Latent Transformer
Part 1 of All you need to know to get started with Byte Latent Transformer
Attention is all you need
Patience is all you need to learn transformers.
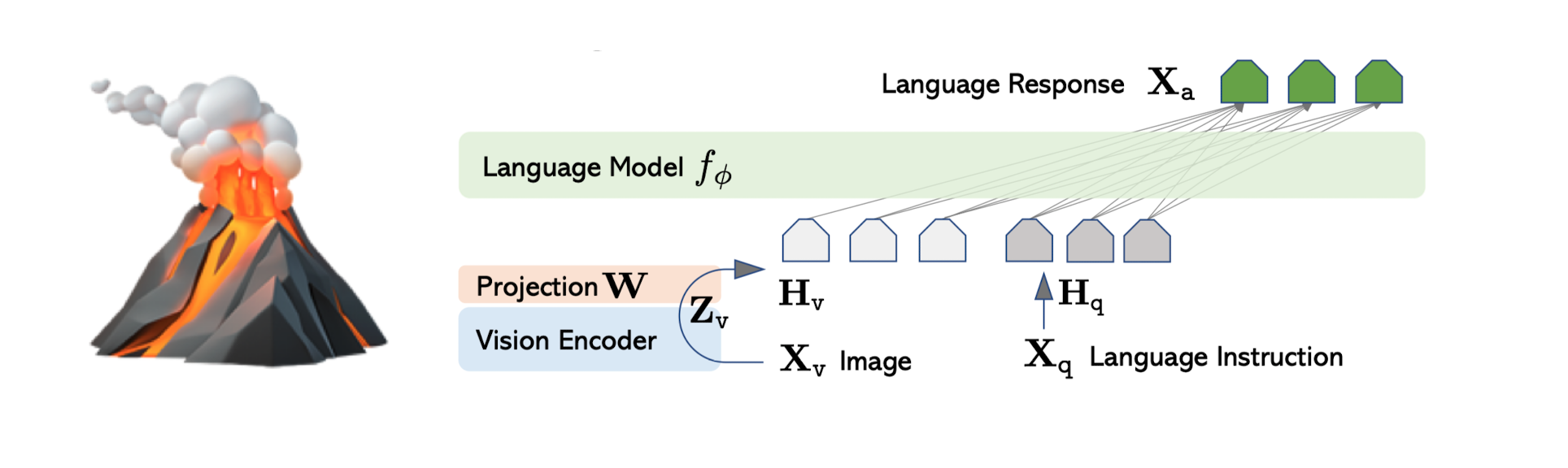
It's LLaVA not lava!
LLaVA = Large Language and Vision assistant ≠ 🌋
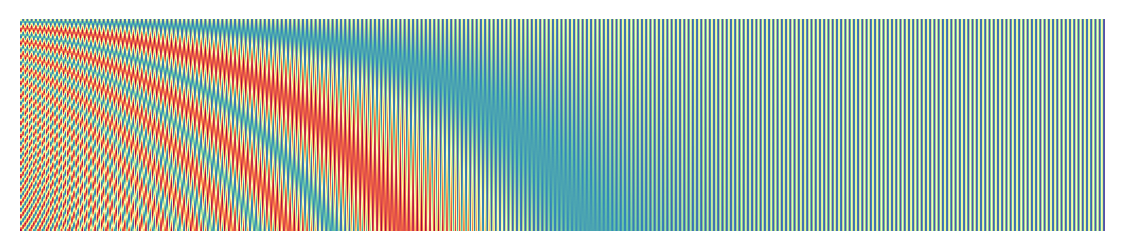
Position Encoding in Transformers
How do you understand position of token in transformer?

Making Misal — India's First Competitive Marathi LLM
How we built Misal 7B/1B — pretraining, custom tokenizer, instruction tuning, and evals for a Marathi-first language model.
Hello super fast blogging!
Exploring static site builder for quick blogging
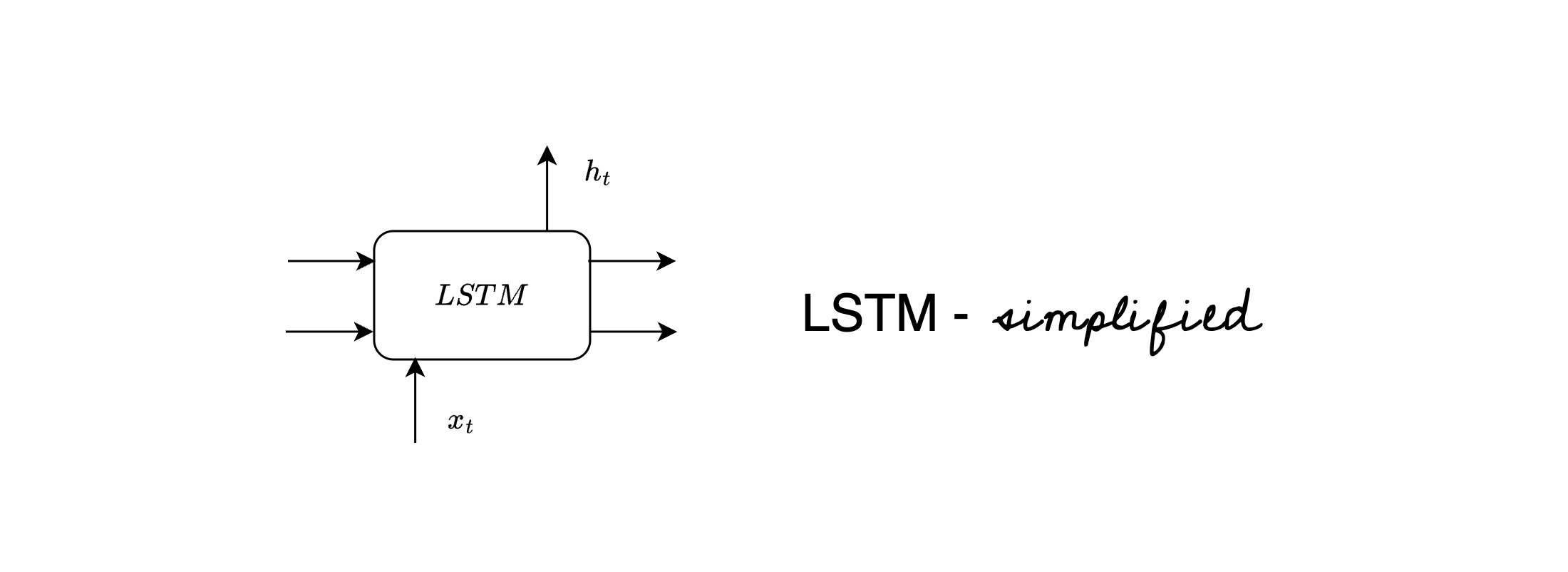
LSTM simplified
In depth and intuitive explanation of LSTM architecture
RNNs a walkthrough
A Brief about Recurrent Neural Networks