Introduction
LoRA or Low Rank Adaptation is one of the techniques which was introduced to train large language model efficiently. To quote it in numbers, using this technique while training GPT3 175B number of trainable parameters can be reduced by 10000x, all while keeping the performance at par or better than fully finetuned model. In this blog i try to condense multiple resources and the nuances that come with this technique.
Refresher on Rank of a Matrix
Some basics first before diving into the concept. Number of linearly independent rows or columns in a matrix is known as rank of the matrix. I like to think of this in a 3D system, where each row is a vector.
Visual guide to rank(M)
Example 1:
What is the simplest 3D system that would be linearly independent? Identity matrix $I_{3}$
$$I_3 = \begin{bmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{bmatrix}$$
Though this matrix is made of 9 numbers it’s information lies across 3 dimensions. In the following representation we can clearly see each vector is linearly independent of each other.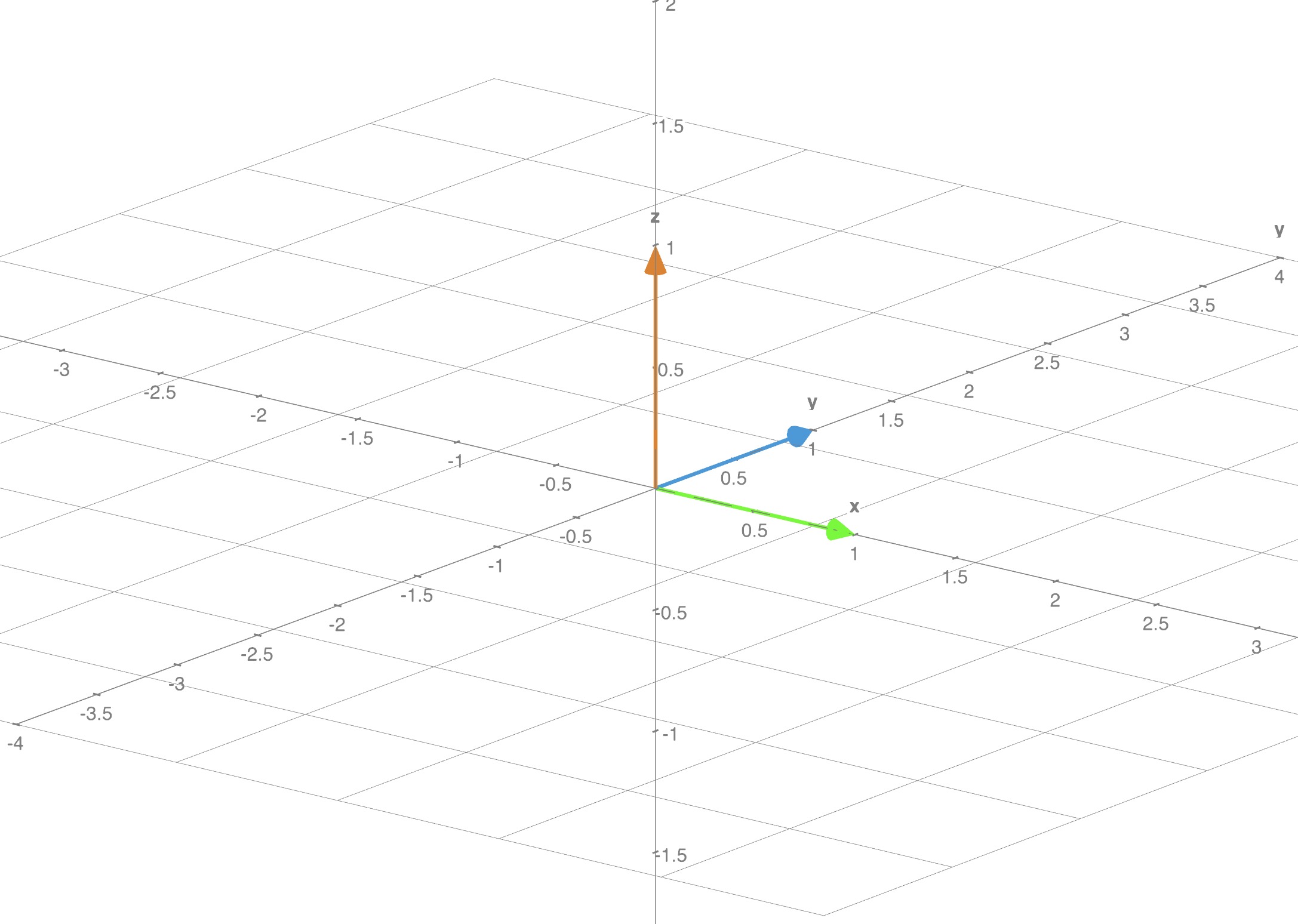
- Rank of this matrix is 3
- No row can be expressed as a linear combination of the other rows
Example 2:
Similarly a set of linearly dependent vectors looks like this:
$$M_{1} = \begin{bmatrix} 1 & 0 & 0 \\ 3 & 0 & 0 \\ 0 & 0 & 0 \end{bmatrix}$$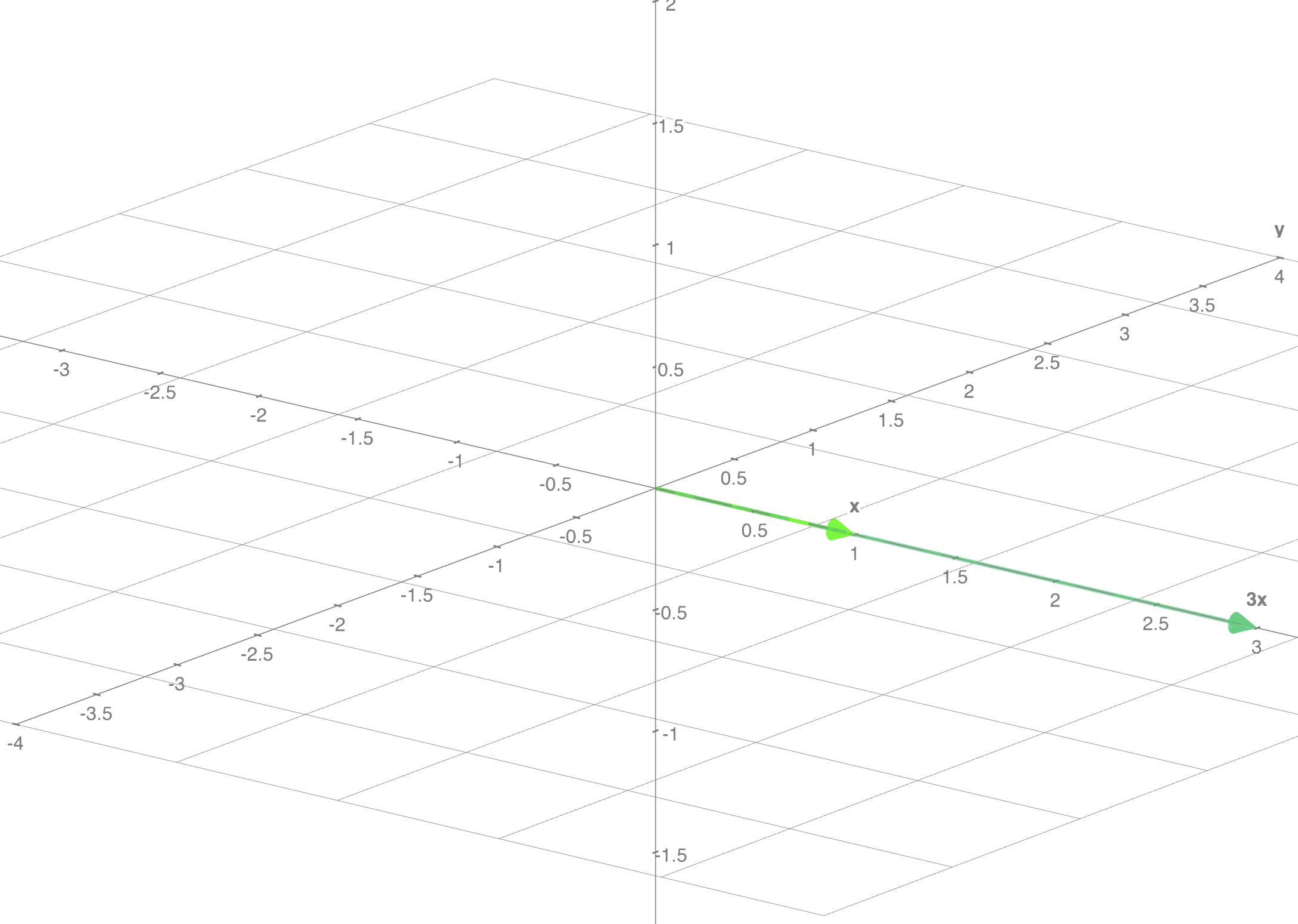
- Rank of this matrix is 1
- Row $r_2$ is 3 times Row $r_1$
Example 3:
Extending the same concept further we can have a matrix with rank 2:
$$M_{2} = \begin{bmatrix} 1 & 0 & 0 \\ 0 & 1 & 1 \\ 0 & 0 & 0 \end{bmatrix}$$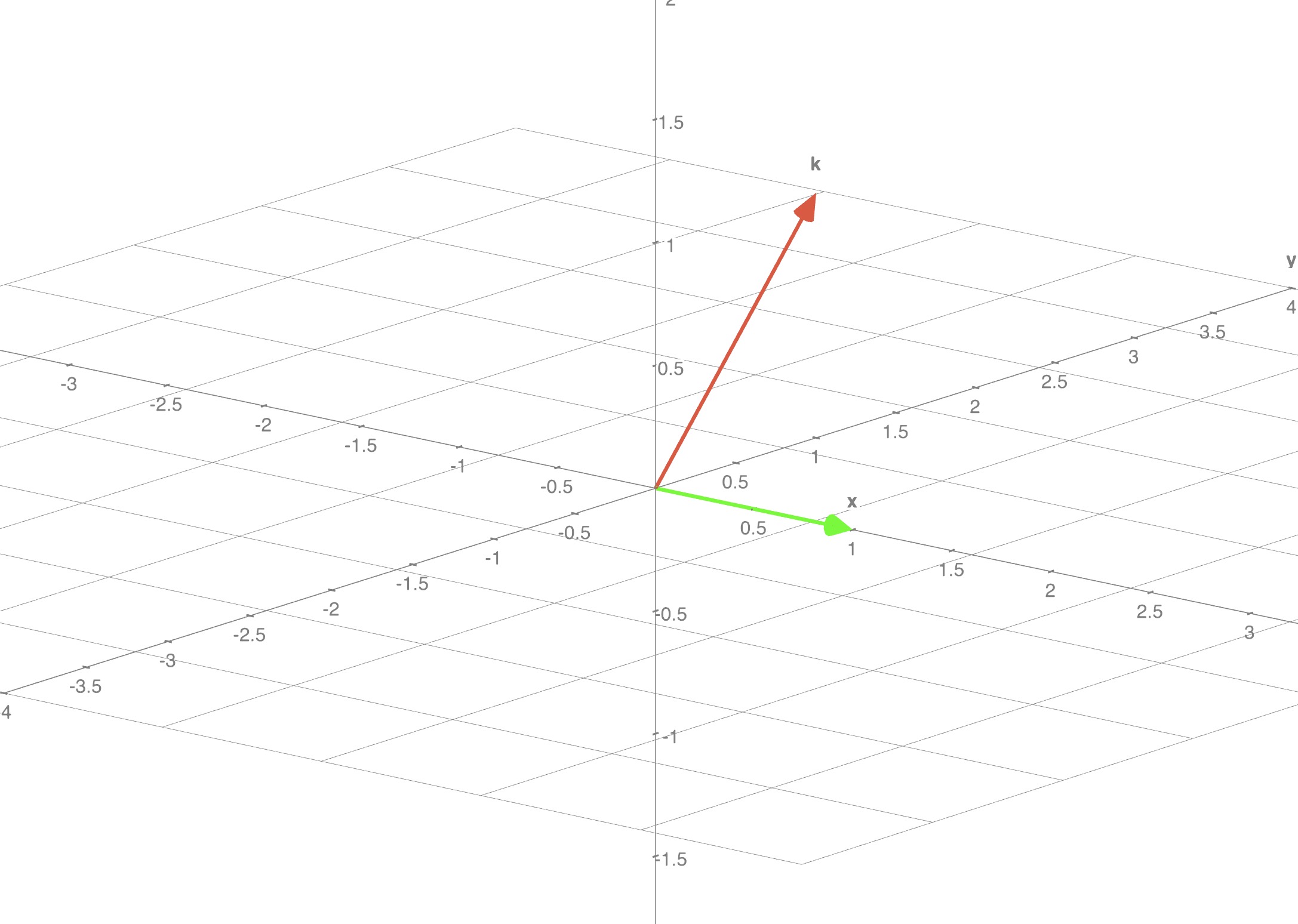
- Rank of this matrix is 2
- Only the first two rows are linearly independent, the third row is zero
Key Properties of Matrix Rank:
| Property | Mathematical Expression | Description |
|---|---|---|
| Upper bound | $\text{rank}(A) \leq \min(m, n)$ | Rank cannot exceed smallest dimension |
| Full vs Low rank | Full: $\text{rank}(A) = \min(m, n)$ | When rank equals smallest dimension |
| Multiplication | $\text{rank}(AB) \leq \min(\text{rank}(A), \text{rank}(B))$ | Product rank is bounded by minimum |
| Addition | $\text{rank}(A + B) \leq \text{rank}(A) + \text{rank}(B)$ | Sum rank is bounded by sum of ranks |
| Subtraction | $\text{rank}(A - B) \leq \text{rank}(A) + \text{rank}(B)$ | Difference rank follows same bound as addition |
| Transpose | $\text{rank}(A^T) = \text{rank}(A)$ | Rank is preserved under transpose |
| Zero rank | $\text{rank}(A) = 0 \iff A = 0$ | Only zero matrix has rank zero |
What is Low Rank Adapter?
Brief
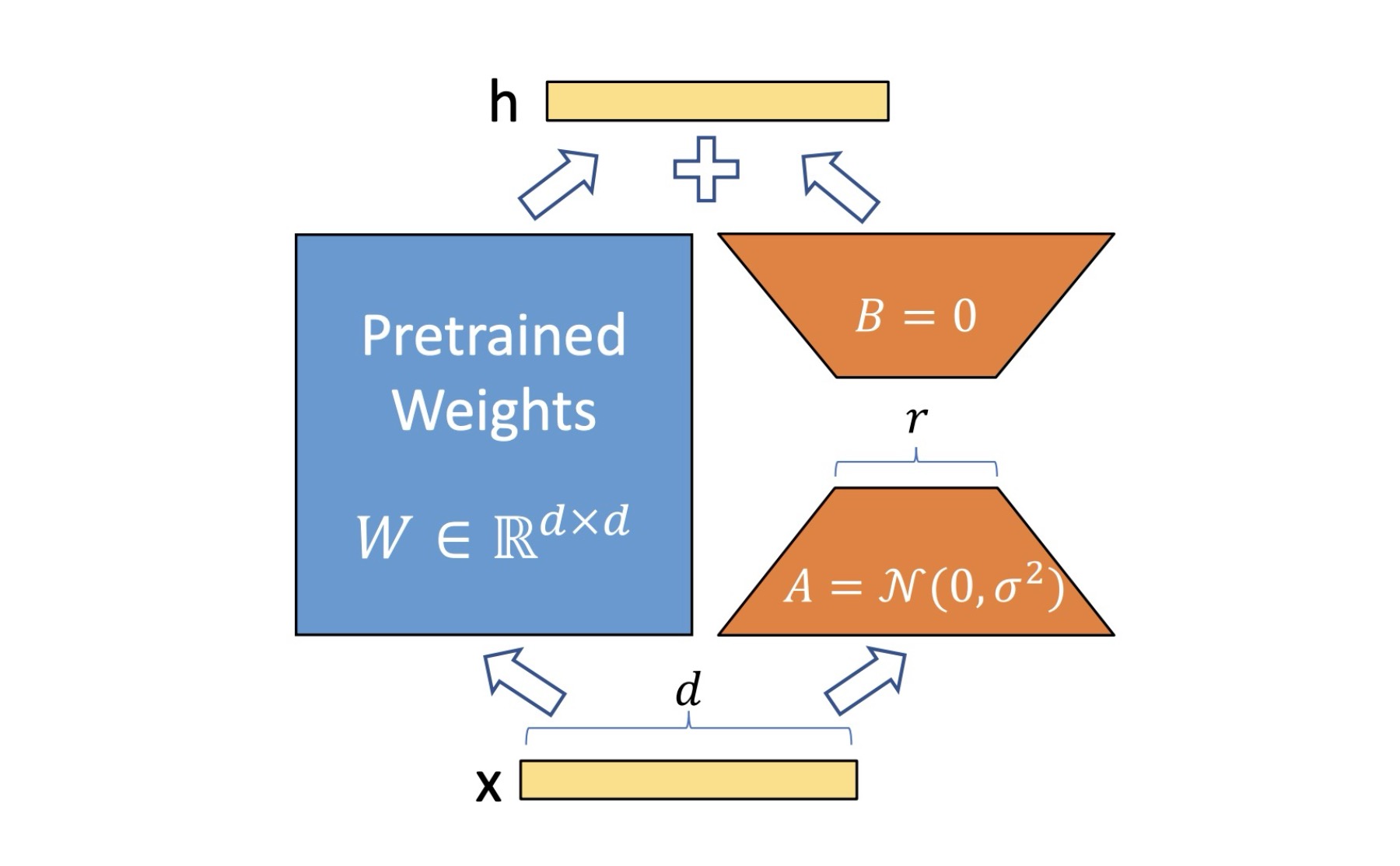
LoRA adds a low-rank update to frozen pre-trained weights. Instead of updating the original weight matrix $W_0$ directly, LoRA keeps it frozen and learns a low-rank decomposition $\Delta W = BA$ to adapt the model:
$$ W = W_0 + \Delta W = W_0 + BA $$
Where: $$ B \in \mathbb{R}^{d \times r}, \quad A \in \mathbb{R}^{r \times d}, \quad W_0 \in \mathbb{R}^{d \times d} $$
With $r \ll d$ (r much smaller than d), making the adaptation parameter-efficient.
Essentially we are trying to learn what $\Delta W$ should be added to existing weights of a model to learn / adapt to a new task.
Visually it looks like this: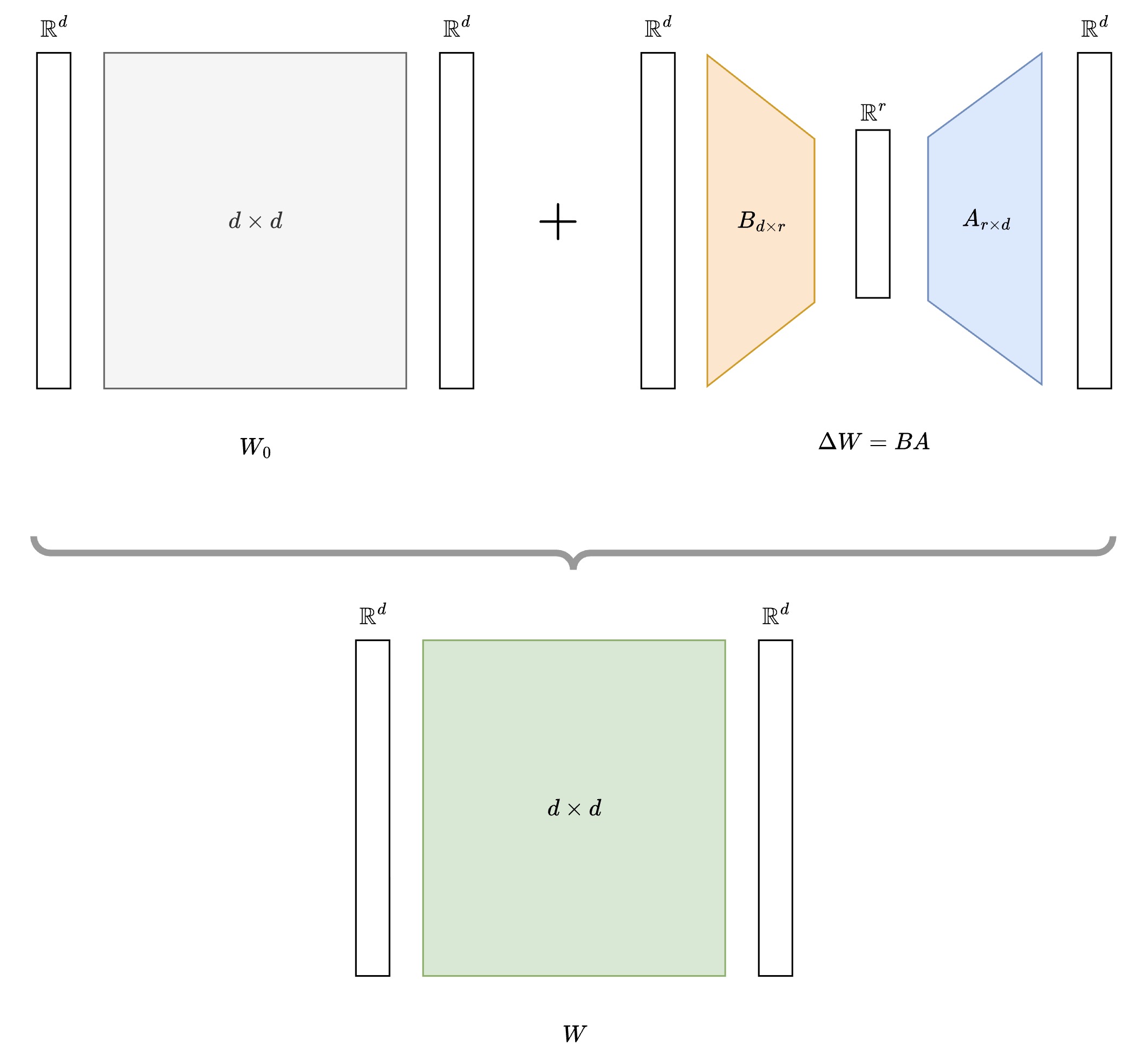
Where does rank fit in?
- Notice $r$ i.e rank in above diagram
- You choose it as a parameter, generally $r \ll d$
- Typically $r \in \{8, 16, 32, 64\}$, and is decided empirically
But how does it imply parameter efficient training?
- Without LoRA, learnable weights were $d^2$
- With LoRA, we only need to learn $ 2dr = (d \times r + r \times d)$ weights
- As $r \ll d$ it reduces number of trainable parameters drastically
Is Rank calculated during this process?
- NO! rank of matrix is not calculated during LoRA training or inference
- When you choose hyperparameter $r$, you are essentially saying that your matrix $B$ or $A$ will have lower rank than the original matrix $W_0$
- Upon multiplication matrices $B$ and $A$ resultant rank will be $min(rank(A), rank(B))$ which will be smaller than $rank(W_0)$
- Key takeaway: You have a rank constraint, you do NOT compute it.
What does rank $r$ determine?
- How much compression you get
- How much expressivity you retain
- How much computation you save
Training: LoRA
During training:
- $W_0$ remains frozen (gradients blocked)
- Only $A$ and $B$ matrices are updated via backpropagation
- Forward pass: $h = (W_0 + BA)x$ where $x$ is input
Visual guide to training LoRA
No Gradients"] matrixA["Matrix $A$
Trainable"] matrixB["Matrix $B$
Trainable"] end subgraph forward[Forward Pass] multiply["$B \times A$"] add["$W_0 + BA$"] output["Output $h$"] end subgraph backward[Backward Pass] gradA["$\nabla A$"] gradB["$\nabla B$"] blocked["$\nabla W_0 = 0$
Blocked"] end input --> matrices matrixB --> multiply matrixA --> multiply frozen --> add multiply --> add add --> output output --> gradA output --> gradB output -.-> blocked style frozen fill:#E3F2FD,stroke:#1976D2,stroke-width:2px style matrixA fill:#FFEBEE,stroke:#D32F2F,stroke-width:2px style matrixB fill:#FFEBEE,stroke:#D32F2F,stroke-width:2px style multiply fill:#E8F5E9,stroke:#388E3C,stroke-width:2px style add fill:#FFF3E0,stroke:#F57C00,stroke-width:2px style output fill:#F3E5F5,stroke:#7B1FA2,stroke-width:2px style gradA fill:#FFCDD2,stroke:#C62828,stroke-width:2px style gradB fill:#FFCDD2,stroke:#C62828,stroke-width:2px style blocked fill:#ECEFF1,stroke:#455A64,stroke-width:2px,stroke-dasharray: 5 5
Key insight: The $\nabla W_0 = 0$ means gradients for $W_0$ are blocked/not calculated. $W_0$ remains completely frozen during training - only the small matrices $A$ and $B$ receive gradient updates. The dotted arrow shows this blocked gradient flow.
Inference: LoRA
During inference:
- Option 1: Compute $W_0 + BA$ once and use merged weights
- Option 2: Keep separate and compute $W_0x + BAx$
- Adapter swapping: Replace $BA$ with different adapters for different tasks
Option 1: Merged Weights
Pre-compute the combined weights once, then use standard inference
Option 2: Separate Computation
Compute base and LoRA paths separately, then add their outputs
Option 3: Adapter Swapping
Keep multiple task-specific LoRA adapters and swap them dynamically
- write about scaling factor and why it is important
- how it is initialized
What does LoRA unlock?
LoRA’s flexible inference approaches enable several powerful capabilities:
No Additional Latency
(Option 1: Merged Weights)
- Once weights are merged ($W_0 + BA$), inference runs at original speed
- No additional latency introduced during inference
- Perfect for production deployment where speed matters
Massive Storage Savings
- Store one base model + multiple small adapters instead of full fine-tuned models
- Example: Instead of storing 10 different 7B models (70GB total), store 1 base model (7GB) + 10 LoRA adapters (~50MB each = 500MB)
- Result: 70GB → 7.5GB (90% storage reduction)
Dynamic Task Switching
(Option 3: Adapter Swapping)
- Keep multiple LoRA adapters in memory simultaneously
- Switch between tasks instantly without reloading models
- Diffusion model example:
- Same base Stable Diffusion model
- Adapter 1: Anime character style
- Adapter 2: Oil painting style
- Adapter 3: Photorealistic portraits
- Switch styles in real-time based on user preference
LoRA and a small neural network
Let’s look at LoRA in action with real experiments on Llama 3.2 1B model. I conducted systematic experiments to demonstrate LoRA’s effectiveness compared to traditional fine-tuning approaches.
Experimental Setup
- Model: meta-llama/Llama-3.2-1B (1.24B parameters)
- Task: Sentiment analysis on IMDB dataset
- Hardware: NVIDIA A10 (23GB VRAM)
- Comparison: Baseline vs LoRA fine-tuning
The Reality of Training Large Models
Baseline Approach (Frozen Layers):
1# Had to freeze first 12/22 layers to fit in memory
2for param in model.model.layers[:12].parameters():
3 param.requires_grad = False
4
5Total parameters: 1,235,818,498
6Trainable parameters: 505,960,450 (40.9%)
7Batch size: 16 (maximum possible)
8Test Accuracy: 87.16%
LoRA Approach:
1lora_config = LoraConfig(
2 r=16, # Rank
3 lora_alpha=32, # Scaling factor
4 lora_dropout=0.1, # Regularization
5 target_modules=["q_proj", "v_proj", "k_proj", "o_proj",
6 "gate_proj", "up_proj", "down_proj"]
7)
8
9Total parameters: 1,247,090,690
10Trainable parameters: 11,276,290 (0.9%)
11Batch size: 16 (same as baseline, but could go higher)
12Test Accuracy: 93.84%
The Dramatic Difference
| Metric | Baseline | LoRA | Improvement |
|---|---|---|---|
| Trainable Params | 505M (40.9%) | 11M (0.9%) | 97.8% reduction |
| Test Accuracy | 87.16% | 93.84% | +6.68% |
| Parameter Efficiency | 0.0017/M | 0.0832/M | 48.3x better |
Memory Reality Check
When I tried true full fine-tuning (all 1.24B parameters):
⚠️ CUDA OutOfMemoryError: Tried to allocate 64.00 MiB
Even with batch size 2 - FAILED on 23GB GPU!
Meanwhile, LoRA succeeded with 8x larger batch size (16):
✅ Peak Memory: 20.57GB
✅ Training successful with much larger batches
Key insight: LoRA doesn’t just make training more efficient - it makes training possible where full fine-tuning fails.
Choosing the Right Rank
The rank $r$ is a crucial hyperparameter that controls the parameter-performance trade-off.
| Rank | Use Case | Trade-off |
|---|---|---|
| $r = 8$ | Simple tasks, maximum efficiency | May underfit complex tasks |
| $r = 16$ | Sweet spot for most tasks | Good balance |
| $r = 32$ | Complex tasks requiring more capacity | More parameters, still efficient |
| $r = 64$ | Very complex tasks | Approaching diminishing returns |
Rule of thumb: Start with $r = 16$, increase if underfitting, decrease if overfitting or need more efficiency.
End note
This brings us to the end of our deep dive into LoRA, from mathematical foundations to hands-on experiments.
But why did i cover this topic? While i was Claud-ing to research about LoRA, an interesting statement was passed by the model:
“The Manifold Hypothesis states that real-world high-dimensional data lie on low-dimensional manifolds embedded within the high-dimensional space.”
It got me thinking, where else can we see this principle in action?
- Facial landmarks: 68 key points capturing the essence of infinite facial expressions
- Image embeddings: Millions of pixels compressed into meaningful feature vectors
- LoRA adapters: Complex model adaptations expressed through low-rank decompositions
All of these suggest that meaningful changes often happen in lower-dimensional spaces embedded within high-dimensional ones. LoRA’s effectiveness might be capturing this fundamental property of how neural networks actually adapt and learn. Beautiful, isn’t it?
All the experiments discussed in this blog have been open-sourced at https://github.com/sagarsrc/lora-experiments/ for you to reproduce and explore further.
I hope you enjoyed this blog. Have fun learning!
References
- LoRA: Low-Rank Adaptation of Large Language Models
- What is Low-Rank Adaptation (LoRA) | explained by the inventor
- LoRA - The Diet Pill for Obese Language Models
- LoRA Experiments Repository