LLaVA paper
In this blog I try to break down some key points in the LLaVA research paper titled “Visual Instruction Tuning”, this is more of me exploring the paper and code/data associated with it and noting it down.
LLaVA is a large multimodal model that is instruction-tuned to understand images and text. The authors present an end-to-end description of the procedure they follow to build this model. Additionally, with data used for training, they also open-source their model.
Let us dive into LLaVA, shall we?
No thanks, I’ll pass.
Data Preparation
As far as data preparation is concerned, it 2 steps are involved.
caption = brief description
Use existing image, caption dataset like CC3M, with caption as an input, create a list of varied questions answers, here answer can be caption or part of catpion. Use this dataset to create instructions of the format:
1"""
2Human: <question> <image>
3Assistant: <caption>
4"""
Though this data is limitting and does not mimic scenarios where a human would ask an AI assistant about the image, it serves as a good objective for pretraining.
gpt-4 = reasoning
Image caption instruction data mentioned above lacks in-depth reasoning and diversity. In order to mitigate this authors use GPT4 to create data by just using captions as an input. Below is the prompt mentioned in the paper.

GPT4 is used for:
- Conversational data: Conversation between assistant and person as as if assistant is seeing image.
- Detailed description: Generate detailed description of image using sample set of questions.
- Complex reasoning: Generate complex questions where answering requires logical breakdown of question and multiple steps to arrive at final answer.
| type | num_records |
|---|---|
| conversational data | 58K |
| detailed description | 23K |
| complex reasoning | 77K |
| total instructions | 158K |
One other key aspect to note in this paper is type of context that was provided to GPT4 while generating data. Apart from captions, paper also mentions using bounding boxes as a context to get a rough understanding of location of objects in the image.

Below is an example of a dummy prompt to GPT4 which includes bounding boxes as input.

We can see GPT4 provides spatial information of desired objects given bounding boxes. This information can be used to create more complex QA pairs for instruction tuning.
NOTE : Paper does NOT use image as input to GPT-4, it only utilizes captions and bounding boxes to construct training data. (see Page 3, 23, 24)
Teaching model to see
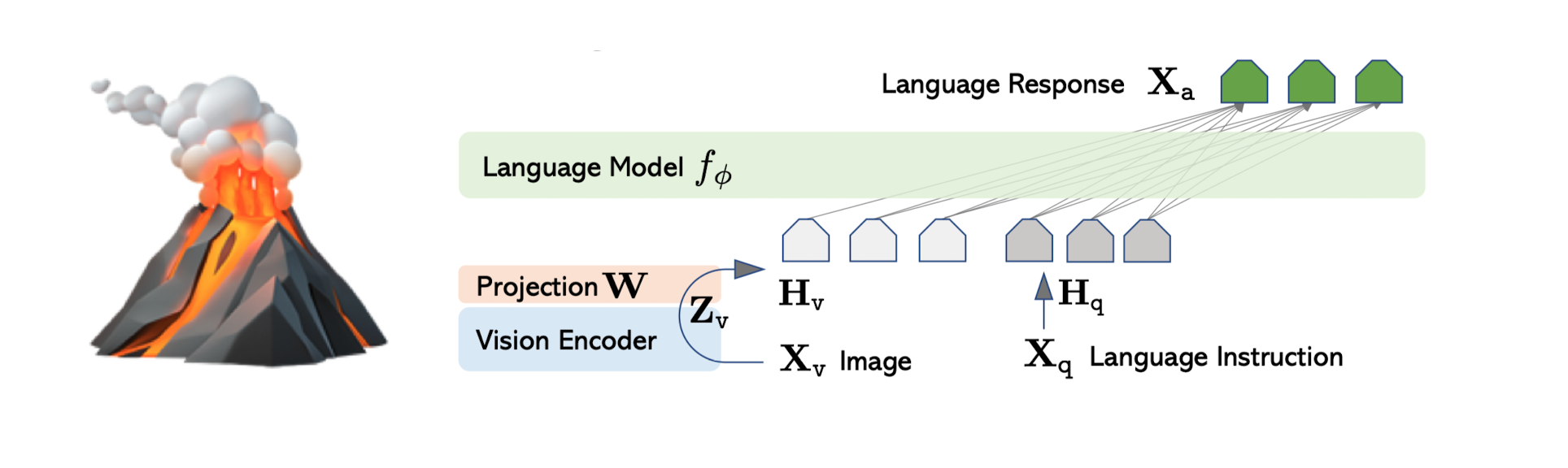
Architecture
LLaVA utilizes 2 pretrained models in their architecture:
- Vicuna 13B - which is a fine tuned derivative of Llama2 13B variant
- CLIP embeddings - architecture known for encoding both text and images
LLaVA training procedure is divided into 2 stages.
Stage 1: Pretraining for feature alignment
CLIP embeddings are present in different hyperspace, plus they cannot be used as an input to LLMs readily because of different dimensionality. Hence to solve for this a projection of these embeddings is obtained using Linear layers. In this stage we keep CLIP embeddings and LLM weights frozen and only learn the weights of this Linear layer.

For training projection layer filtered CC3M image text pairs dataset was used. Each sample was treated as single turn conversation. Learning task was to predict caption given image and a question (generated by GPT4) associated with it.
Sample of pretraining data:
Stage 2 : Fine tuning end to end
Visual encoder layers are kept frozen, only projection layer and LLM weights are learnt in this stage. Here the instruction tuning data is used conversation, complex reasoning and description instructions which were created using GPT4. As a result of this a multimodal chatbot is obtained.
Sample of Instruction tuning data:

Going through code & data
LLaVA model architecture
Here is trimmed down architecture of LLaVA model.
1LlavaForConditionalGeneration(
2 (vision_tower): CLIPVisionModel(
3 (vision_model): CLIPVisionTransformer(
4 (embeddings): CLIPVisionEmbeddings(
5 (patch_embedding): Conv2d(3, 1024, kernel_size=(14, 14), stride=(14, 14), bias=False)
6 (position_embedding): Embedding(577, 1024)
7 )
8 ...
9
10 (post_layernorm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
11 )
12 )
13 (multi_modal_projector): LlavaMultiModalProjector(
14 (linear_1): Linear(in_features=1024, out_features=4096, bias=True)
15 (act): GELUActivation()
16
17 (linear_2): Linear(in_features=4096, out_features=4096, bias=True)
18 # ^^^^^^^^^^^^ note
19 )
20 (language_model): LlamaForCausalLM(
21 (model): LlamaModel(
22
23 (embed_tokens): Embedding(32064, 4096)
24 # ^^^^^^^^^^^^ note
25 (layers): ModuleList(
26 (0-31): 32 x LlamaDecoderLayer(
27 ...
28
29 )
30 (norm): LlamaRMSNorm()
31 )
32 (lm_head): Linear(in_features=4096, out_features=32064, bias=False)
33 )
34)
Notice how multi_modal_projector is being used to convert 1024 dim CLIP embedding to 4096 dim embedding using linear layers.
NOTE: Above is the architecture of LLaVA-1.5 where 2 Linear layers are used in Projector as whereas first version of LLaVA has only 1 Linear layer.
handle image and text
Method _merge_input_ids_with_image_features is crucial in class LlavaForConditionalGeneration. This is where image embeddings are plugged in with text embeddings, and new positions are calculated along with image embedding. Additionally respective attention masks are created to pass down to the model.
Example of Instruction to model:
1Human: Provide a brief description of the given image.\n<image> <STOP>
2Assistant: olive oil is a healthy ingredient used liberally. <STOP>
Below is a rough sketch for the same.
End note
This brings us to an end of walkthrough of a multimodal model LLaVA, main takeaway for me was how image features are aligned and integrated into model while accounting for position of image embeddings before passing to the model.
I hope you enjoyed this blog. Have fun learning!
References
- LLaVA arxiv
- github modeling_llava.py
- huggingface - LLaVA-CC3M-Pretrain-595K
- huggingface - LLaVA-Instruct-150K